产品服务
大数据
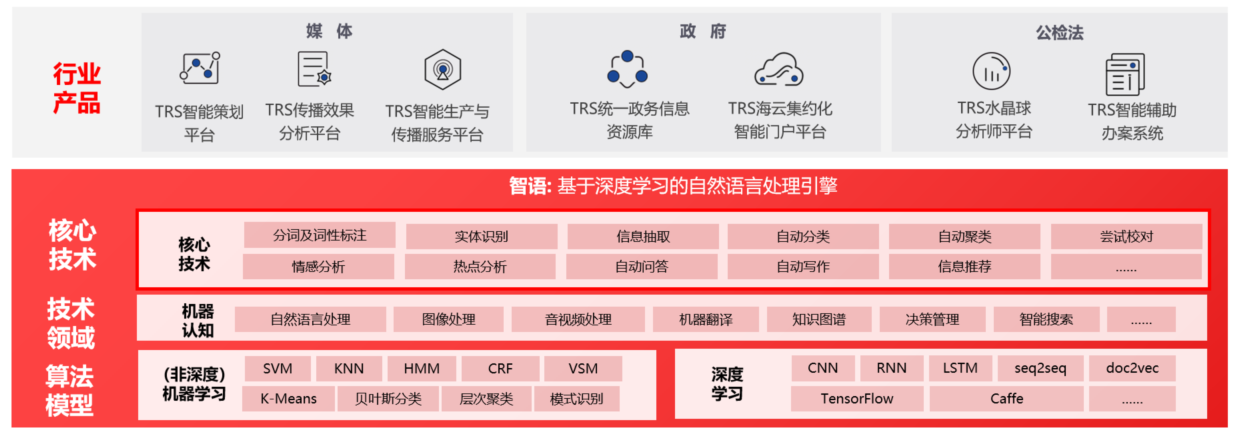
人工智能
安全
其他
行业方案
数字政府
媒体融合
网络空间治理
公共安全
知识产权
企业数字化转型
金融科技
出版
服务与合作
文档中心
产品授权
生态体系
了解我们
公司简介
新闻活动
行业洞察
投资者关系
产品服务 >>
行业方案 >>
投资者关系 >>