近日,拓尔思信息技术股份有限公司自主研发的TRS海文自然语言处理引擎V9.0版本(TRS DL- CKM V9)正式对外发布。该引擎吸收了拓尔思在自然语言处理和信息检索领域多年的技术积累,围绕深度学习、知识图谱等核心技术,依托TRS智拓语义智能技术平台等技术成果,面向智慧专利、智慧公安、智慧政务、智慧金融、开源情报分析等应用场景,以先进的NLP技术为用户的业务应用赋智赋能。
截至目前,TRS DL- CKM 系列产品已服务超过1000+企业级客户。新发布的TRS DL- CKM V9更是在功能和性能等方面有了显著提升,受到了业界的广泛关注。这里,小编整理出大家最关心的六个问题,并请海文自然语言处理引擎V9的产品负责人进行提纲挈领的清晰解答。
Q1:TRS DL-CKM V9的产品定位与优势?与TRS智拓语义智能技术平台的关系?
TRS DL-CKM V9作为基于深度学习的自然语言处理引擎,是构建在TRS智拓语义智能技术平台上的核心组件,融合深度学习、知识图谱等技术,功能完备,案例丰富,能够为用户提供一站式NLP服务能力。
TRS DL-CKM V9依托TRS智拓语义智能技术平台进行AI模型的构建,其自带一组预先训练好的AI模型,供用户直接使用。此外,基于用户的自有数据AI模型研发需求,可使用数据智能标注平台构建自己的行业数据标注集,然后通过“智拓”平台进行AI模型训练,并发布到TRS DL-CKM V9上进行实际生产运行。
Q2:TRS DL-CKM V9 与TRS DL-CKM V8相比,功能特性有哪些提升?
TRS DL-CKM V9在功能、性能和应用效果等各个方面都有了大幅度提升,具体表现在:
1.新增多个深度学习接口
新增一批基于深度学习的接口,包括自动分类、情感分析、文本纠错、自动摘要、深度特征提取、短文本相似度、文本改写等。通过引入Bert等预训练模型、图神经网络以及知识图谱的融合等技术,应用效果比对应的机器学习接口均有不同程度的提升。
这里,以自动分类为例,VGCN+BERT的分类方法比传统分类方法有大幅度提升。
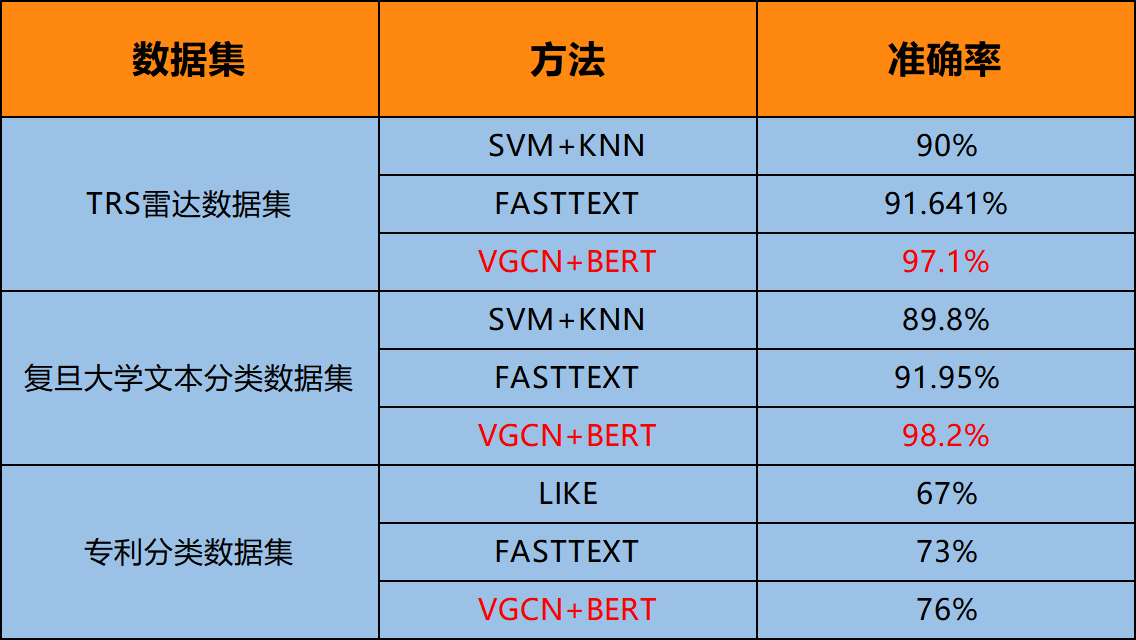
2.个性化的模型训练
与智拓语义智能技术平台紧密结合,通过“智拓”结合领域数据训练个性化的AI能力模型。自带一批预训练AI模型,包括基于BERT、XLNet、ALBERT等预训练模型,CNN、RNN、LSTM、Transformer、VGCN等神经网络模型,以及分类、实体、关系等诸多功能的高质量标注语料,用户可通过预训练模型+行业数据微调的方式,快速有效地使用。
3.功能更加丰富
新增多语种实体识别、实体链接、句法分析、事件抽取等接口。
4.接口易用性高
使用RESTful接口,只需通过标准的HTTP客户端即可调用,且自带web版演示程序,方便用户使用。
5.接口性能提升大
Rest服务器接口性能有了较大提升,多并发吞吐量比前一版本平均提升50%以上。
Q3:TRS DL-CKM V9为何要引入深度学习模块,并同时保留机器学习模块?
目前,深度学习技术几乎在NLP的各个领域都取得了很好的效果,因此TRS DL-CKM V9吸收了深度学习的最新成果,包括预训练模型、图神经网络等技术,通过知识图谱与深度学习的融合,提升NLP的处理效果。
但深度学习不是万能的,想取得好的应用效果,需要有高算力计算设备(GPU、NPU、FPGA等)和大量标注数据的支持。从性能和效果两方面综合考虑,传统机器学习模块的精度稍低一些,但计算费用低,在普通服务器上也能有较高的运行速度和较好的执行效果;深度学习模块的精度高一些,但计算资源需求高,运行速度相对较慢,需要GPU卡等高算力设备支持。
因此,TRS DL-CKM V9可同时提供深度学习和机器学习的两类模块,供用户根据实际情况进行选择。
Q4:TRS DL-CKM V9与其他NLP平台相比,主要差异在哪里?
目前,国内外很多软件公司包括BAT等互联网公司都推出了自己的NLP平台,此外,也有一些开源的NLP软件。对这些云平台而言,它们主要提供基本的通用型NLP在线服务,而一般不提供个性化定制和本地化部署。用户想开发特定功能或引入自己的行业数据资源,需要依托人工智能平台进行训练和开发,开发成果通常也只能部署在云平台上;而对于开源NLP软件而言,主要是专注于基本的通用型的NLP功能,个性化定制一般需要靠用户自己去阅读和修改代码,对各种环境的适配也都需要自己开发。
与这些NLP平台相比,TRS DL-CKM V9无论在定位还是适用范围上,都有很多独有特色,主要体现在:
1.TRS DL-CKM V9 具备几十种NLP功能组件和几百个调用接口,功能完备、体系完整,具有较为完整的NLP和视频等AI服务能力,在TRS生态下,可以提供一站式AI解决方案。
2.TRS DL-CKM V9具有20多年的NLP自主研发历史,拥有大量的用户案例和实际行业经验,积累了大量的行业语料、词典、知识图谱等资源以及行业分析模型,有专业的技术人员和项目实施人员,与用户深入合作,提供专业化的解决方案和服务。
3.TRS DL-CKM V9可与TRS智拓语义智能技术平台无缝集成,借助智拓提供的智能数据标注和AI模型训练能力,可以根据用户需求进行个性化定制,包括智能标注自有的行业数据,开发和训练专有的AI计算模型。
4.TRS DL-CKM V9支持本地化部署,同时支持云环境部署(包括公有云和私有云),支持全国产化软硬件系统,适应不同应用场景。
Q5:知识驱动的AI是目前的发展方向,TRS DL-CKM V9的知识驱动主要体现在哪些方面?
深度学习目前面临着模型的可解释性和可信度两大难题:
1.可解释性
近年来,深度学习在图像、声音、自然语言处理等领域取得巨大进步,但其可解释性依旧是个难题。通过算法训练出的模型被看作成黑盒子,严重阻碍了机器学习在某些特定领域的使用,譬如医学、金融等领域。
2.可信度
实践中,人们越来越多地发现深度学习模型的结果往往与人的先验知识或者专家知识相冲突。如何让深度学习有效利用大量存在的先验知识,提高模型的可信度,已成为当前深度学习领域的重要挑战。知识图谱本身是一种图结构数据,采用图构建知识和数据之间的关联,同时应用图神经网络技术,有望结合知识和数据实现更好的可解释和可信人工智能技术。
TRS DL-CKM V9的知识驱动体现在两个方面:
1.在深度学习模型中融入行业语义知识,主要是利用图神经网络在学习节点、边表示上的优势,进行知识表示学习,包括融合知识图谱的预训练语言模型、基于知识图谱的图表示学习模型等,通过知识驱动+大数据驱动提升AI学习效果;
以智能文本校对应用为例,为了解决语义校对这一难题,TRS DL-CKM V9采用了语义知识结合深度学习的方案。首先使用语义分析、关系抽取等技术提取文本中的结构化知识,并将其进行噪音替换,生成语义校对知识数据集,包括汉语成语语义、历史知识、人名-职务、地区-归属等数据集,通过Attentive Reader (AR)、SpellGCN等深度学习模型将文本转化为蕴含上下文实体关系信息的编码向量,从预训练模型包含的大量知识中学习到词语之间潜在的语义关系,有效地提高模型的语义知识推理能力。实验表明,该方法可以有效地识别出文本中存在的语义知识错误,相比传统方法有了较大提升。
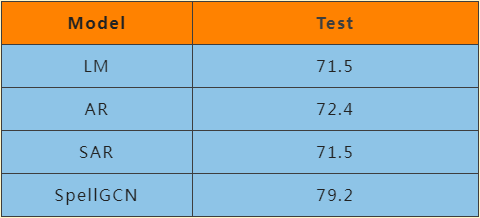
2.专注研发基于知识图谱的智能应用,具体包括在知识图谱自动构建基础上,研发了基于知识图谱的机器写作、智能问答、事件分析等功能,通过利用图神经网络在信息传播和推理上的优势,有效地在应用任务中引入知识图谱中的信息,提供更具可信度和可解释的应用模型。
以某事件库项目为例,TRS DL-CKM V9为用户实现了一种面向互联网开源情报领域的事件分析与推演解决方案,具体包括:
· 提供基于BERT+GCN的开源事件模型构建与分析工具,帮助用户自动构建互联网新闻事件库和虚拟事件库,实现了事件图谱自动构建与动态追踪;提取事件之间的逻辑关系,生成事件脉络图,构建事理图谱,并实现可视化分析;
· 基于强化学习技术(RL)和知识推理等技术,构建事件的推演预测平台,实现虚实结合的机器智能事件推演与预测。
Q6:TRS DL-CKM V9是否支持云计算,未来有怎样的发展规划?
TRS DL-CKM V9未来的发展方向包括如下几方面:
1.提供在线服务平台,既可以部署在公有云也可以部署在私有云上,支持按需调用,服务于云计算等应用场景;
2.探索行业数据、知识图谱与预训练模型的融合技术,通过领域知识的注入和引导,提升NLP可信度与应用效果;
3.探索知识图谱与图神经网络的有效结合方式,针对分类、推荐等典型应用,提供融合深度学习与知识推理的可解释性框架。




