专利检索与服务系统(Patent search and service system),以下简称S系统,是专利局信息化建设十一五规划中的重大建设项目之一。S系统的系统架构设计是基于B/S架构进行开发设计的。审查员在确定检索词或检索式后,点击“检索”向服务器(à检索WEB服务器à检索应用服务器)发送请求,服务器在接收到该请求之后,会调用检索引擎的检索接口进行检索并将检索式注册到应用数据库中,然后返回检索结果。
TRS检索引擎作为S系统的发动机,提供专利各类数据的索引和检索服务,包括专利分类号、公告日、申请人、设计人等结构化数据的元数据检索,以及专利名称、摘要、权利要求书、说明书等非结构化数据的全文检索。
搜索引擎功能实现了91个索引库、23.1亿条索引记录、超20T的数据量,日均访问量2500万次,总请求平均响应时间低于60毫秒,记录读取平均响应时间低于50毫秒。
特点:
支持跨语言检索
支持数值范围检索
提供查询和统计分析功能
支持文本搜索,支持机械附图搜索
支持关键词检索,支持语义检索
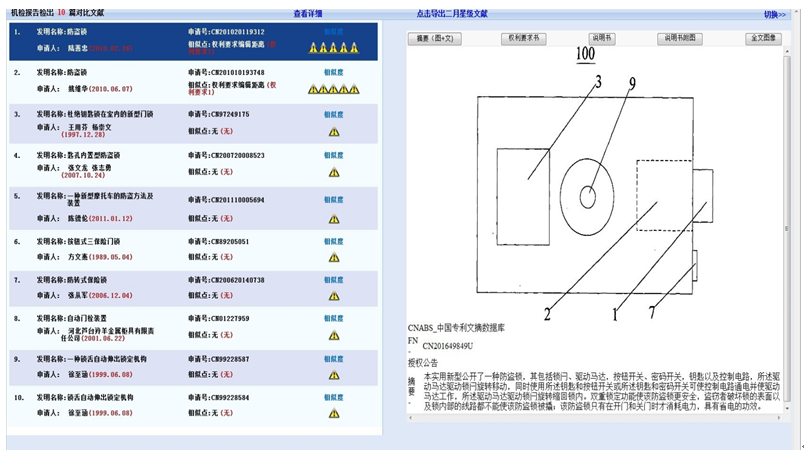
随着我国从“中国制造”市场向“中国设计”市场转型,国家大力推动各个重大领域的技术创新,我国的专利申请数量在快速上升,每年的专利申请数量已居国际前列。随着申请量的飞速增长,恶意抄袭、低质量申请等问题在专利申请中层出不穷。庞大的专利申请对审查员的日常审查业务造成了巨大的压力,为了减轻审查员的工作负担,提高专利审查质量和公信度,国家知识产权局于2013年上线了实用新型机检报告推送项目。经过几年的努力,已经建成一体化的机检报告生成系统,将申请接收、机检报告生成、机检报告结果推送等功能紧密结合,实现机检报告业务的全流程服务。
目前,已经处理了近大几百万件实用新型申请。其中有10%左右的申请被判定为存在高相似度(四五星)文献,高相似度文献识别的准确率基本是100%。
发明机检报告系统也已经上线,累计已处理发明申请几百万万件(含历史申请),其中有超过10%以上的申请被判定为四五级,即确定为抄袭。四五级识别的准确率基本是100%。
| 时间 |
申请件数(万件) |
四五星文献检出量(件) |
四五星文献检出率 |
| 2013 |
83 |
72464 |
8.7% |
| 2014 |
101 |
48147 |
4.8% |
| 2015 |
109 |
121993 |
11% |
| 2016 |
138 |
247962 |
17% |
| 2017 |
157 |
118115 |
7.5% |
| 2018.1~11 |
198 |
275844 |
13.8% |
机检报告系统总体运行稳定,能够有效地识别出权利书、说明书、附图明显抄袭的申请。
机检报告系统为专利审查工作提供了强有力的智能支持,降低审查开销,促进审查资源的有效利用,切实推动专利审查质量的提升。
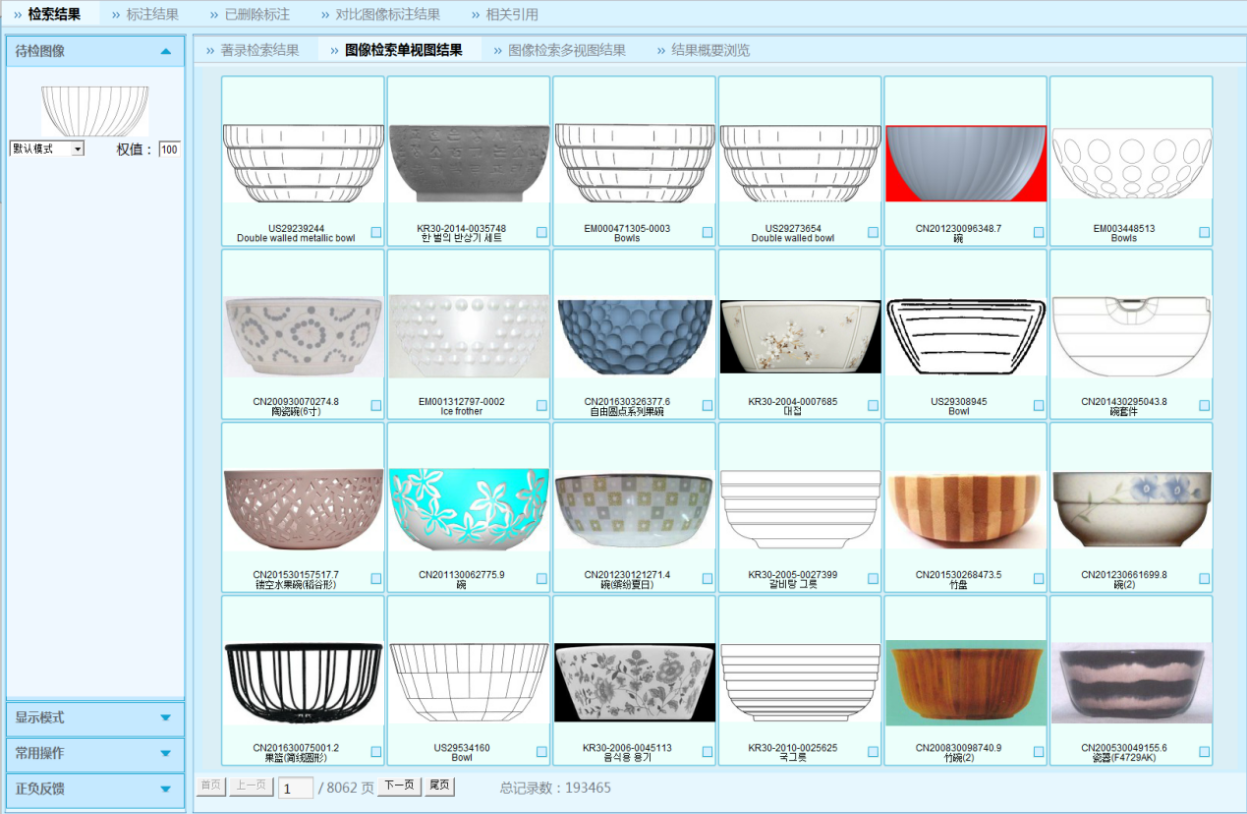
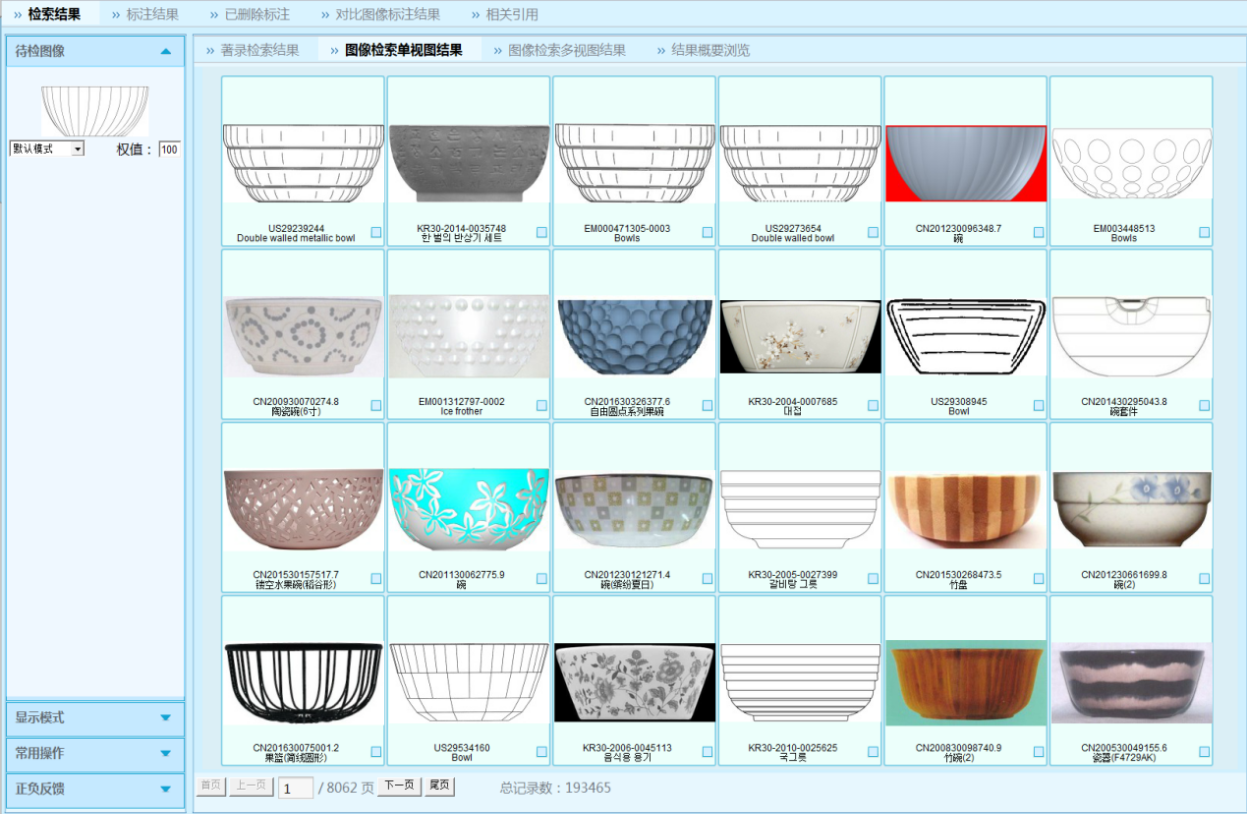
中国外观设计智能检索(以下简称D系统)具有智能化自动识别功能、高效准确的外观设计专利图形图像计算机检索系统, 是支撑国家知识产权局专利局审查工作的核心业务系统之一。
D系统基于计算机图形图像识别与检索技术,依据一定的规则通过对外观设计专利的图形图像进行自动识别和基本判断,快速做出相同/相近似的初步判断,准确过滤无价值的设计,将有价值的检出对象框定在最小范围内,使审查员对检索系统检出的有限数目对象进行相同/相近似的人工判断。
外观设计专利数据具有数据量大,数据类型复杂、图像没有统一标准等特征,因此在外观设计专利数据上进行图像检索有很大的技术难度。D系统二期虽具备图形检索的功能,但存在检索效率慢、检索规模受限和检索效果欠佳等问题。
拓尔思经过多年的研究实践,实现前沿的图形比对和图像检索技术,通过基于图形内容的检索,满足了审查用户对检索效率和准确率需求;结合审查员检索报告的汇总、分析和总结,形成了新的检索模式进而提高检索效率;并集成同近义词扩展、跨语言扩展等辅助技术,进一步提升了检索体验。目前图像检索系统的D系统三期,支持包括中国、美国、日本、韩国、德国、WIPO、中国香港、中国澳门、中国台湾等十多个国家、组织和地区的外观设计专利数据检索。
图像检索系统中在库专利文献数超过900万件,视图数量在4500万幅以上,数据容量达5T以上,实现了“90%的图形检索任务都在5秒内完成检索响应”的性能指标,超越了“90%以上的对比文件出现在检索结果的前15%”的准确率指标。
DI inspiro系统是由知识产权出版社有限责任公司开发建设的新一代知识产权服务系统,是中国首家知识产权大数据与智慧服务的信息化应用工具,聚集了专利、商标、标准、期刊和法律文书等各类知识产权数据。可实现用户对知识产权相关数据的同步检索获取、快捷统计分析和项目即时预警;满足用户对知识产权数据的个性化加工、项目的自主分级管理,以及集团内的信息共享;实现用户的特定需求,如生物序列检索、化学结构检索、可视化检索、侵权分析、聚类分析、关联分析、预警设置和项目管理等。
DI Inspiro充分借鉴了国内外著名信息检索系统的先进功能,并且针对国内用户的使用习惯进行了改良性设计。具有数据全面可靠、功能专业、检索效率高、用户界面友好等特点,是企事业单位研发工程师、专利管理人员和专利咨询师等相关人员进行技术调研、竞争性分析和法律风险预警的有力工具。
DI Inspiro提供了快捷检索、表格检索、号单检索、可视化检索、化学结构检索和生物序列检索等多种检索方式。此外,DI Inspiro还配备了功能强大的辅助查询工具,可实现IPC、专利权人、同义词、国别代码、省市代码、号码等字段的扩展检索。用户可以对检索结果进行导出、收藏、统计筛选和在线分析,还可以对检索策略和结果在线自建数据库导航树,实现保存和预警。


为了满足商标申请用户和社会公众对商标数据信息的检索需求,国家工商总局于2004年建立了商标网上检索系统,为用户免费提供商标注册信息检索服务。
系统主要提供如下服务:
近似检索:在申请商标前,检索被申请商标是否有相同近似,避免申请人的时间和经济损失;
综合检索:用户检索商标的基本信息及其他业务信息;
状态检索:检索商标的业务流程;
公告检索:检索公告信息;
错误反馈:如果发现商标信息有误,可以通过填写反馈单,商标局进行核实后会进行更正。
商标网上检索自动化系统提供五种检索服务及错误信息反馈功能,检索服务包括:商标近似检索、商标综合信息检索、商标状态检索、商标公告检索和商品/服务项目检索。
商标网上检索系统将采用国产化、自主化为主的可扩展、动态配置技术路线。

专利导航,以专利信息资源利用和专利分析为基础,把专利运用嵌入产业技术创新、产品创新、组织创新和商业模式创新之中,是引导和支撑产业科学发展的一项探索性工作。专利导航的主要目的是探索建立专利信息分析与产业运行决策深度融合、专利创造与产业创新能力高度匹配、专利布局对产业竞争地位保障有力、专利价值实现对产业运行效益有效支撑的工作机制,推动产业的专利协同运用,培育形成专利导航产业发展新模式。
专利导航分析系统实现了专利信息资源整合,依据规则粗加工和自动标引,从产业发展方向、城市产业定位、产业发展路径三个维度提供决策参考。专利导航分析系统主要由数据交换系统、智能辅助标引系统和导航分析系统构成。

数据交换系统通过WEB Service接口定期从国家平台获取中外文专利题录文摘数据,同时调用智能辅助标引系统获取技术分支,根据来源EXCEL历史标引数据标引技术分支,以及提取城市、发明人等导航分析关键属性后,写入发布分析库,完成数据交换。
智能辅助标引系统在基于规则(检索表达式),完成技术分支标引;
导航分析系统基于现有专利数据分析,分析维度为技术分支表、IPC分类、城市、申请人等相关属性。
导航分析分为产业发展方向、城市产业定位、产业发展路径三大模块。每个模块细分为若干子分析,分别生成图表及表格。用户可以对相应的分析进行单项及多项下载操作。